Imagine if you had to pay a personal visit up front to the head office of every website you planned to use, in order to pick up an encryption key to keep your traffic secure.
Up to about 1970, ‘received wisdom’ said that was the only way to do digital communications securely… until mathematicians on both sides of the Atlantic decided to challenge that orthodoxy.
The rest is history, and this is that history.
The trouble with secrets
In Part 1, we wrangled with a long-running problem in the world of cryptography.
From at least Julius Caesar’s day, more than 2000 years ago, we’ve known how to use secret writing (which is just the Greek-derived word cryptography written out in plain English) to keep vital documents secure when they can’t reliably be locked away and kept safe by traditional means.
Military campaigns and diplomatic missions are obvious examples of environments in which you might need to send a top-secret message to someone on your own side, yet be forced to transmit the message insecurely.
One trick is to use what’s known as a secret-key encryption algorithm, by means of which a short and easily-hidden ‘lock code’ that was agreed securely in advance can later be used to scramble very much longer messages for transmission via insecure channels.
At the other end, the recipient can unscramble the message privately using that same secret key to unlock it.
But safely sharing those pesky secret keys in advance is a difficult, slow, and expensive process that gets harder and costlier as you increase the number of people who need to communicate securely.
The arithmetic formula for the number of unique pairs in a group of N people is N(N-1)/2, or (N2-N)/2, which is proportional to the square of N. 10 people need 45 distinct keys to communicate securely one-to-one; 100 people need 4950 keys; 1000 people would need an astonishing 499,500 different keys between them.
Challenging the orthodoxy
As we wrote last time, the belief that a pre-shared secret key was the only possible way to communicate securely was part of cryptographic ‘received wisdom’ until recently:
“No matter how much the cost and complexity of secure key distribution might be reduced, it seemed it would always and inevitably be a part – perhaps the most expensive part – of any cryptographic system.”
Even the late, great British cryptographer James Ellis, who is the hero of the story that follows, admitted in 1987 that until the end of the 1960s, he too assumed that what he called non-secret encryption, where a secure channel would not be necessary to exchange secret keys in advance, was a fool’s errand:
The story begins in the 1960s. The management of vast quantities of key material needed for secure communication was a headache for the armed forces. It was obvious to everyone, including me, that no secure communication was possible without a secret key, some other secret knowledge, or at least some way in which the recipient was in a different position from an interceptor. After all, if they were in identical situations how could one possibly be able to receive what the other could not? Thus there was no incentive to look for something so clearly impossible.
But Ellis, working in secret for the British government, ended up not only challenging this orthodoxy head-on, but also writing a report proving that pre-shared secret keys were not a mathematical necessity for secure digital communication:
“[S]ecure messages can be sent even though the method of encipherment and all transmissions between the authorised communicators are known to the interceptor.”
Ellis wasn’t able to come up with a practical mathematical algorithm to make his system work, but he did provide what’s known as an existence proof, showing that received wisdom about the need to share secret keys in advance was wrong, and suggesting strongly that “a [practical] solution probably does exist.fr”
Ellis’s theoretical construction is gloriously straightforward – one of those things that is ‘obvious once someone else has thought of it’ – and doesn’t require mathematical expertise to understand.
It’s worth digging into Ellis’s report to get a feeling for how his thinking went.
An existence proof in pictures
Let’s start with the sort of secret-key encryption system that Ellis hoped to improve upon, where we still need to share the secret key securely in advance.
We’ll simplify things enormously and imagine we have just six different possible inputs to encrypt (A to F), and six different secret keys to choose from for the scrambling process (1 to 6).
We can represent our secret-key encryption system as two grids.
The first grid tells us which ciphertext (encrypted data) to write down for each possible plaintext input (the unencrypted version), for each possible key.
The second grid is simply the first grid inverted, so we can look up every ciphertext under every possible key, thus finding out how to decrypt it and get the original plaintext back.
The Caesar cipher, for example, which shifted every letter along by a fixed number of places, would have its encryption and decryption process encoded like this, assuming a six-letter alphabet with six possible shifts:
Clearly, this isn’t much of a scrambling system, because the tables reveal an obvious pattern to the process, making it predictable and non-random.
But we can convert this into a system with no predictability or exploitable patterns at all by using a truly random permutation of the inputs A to F for each key 1 to 6:
This system isn’t secure, of course, despite its randomness, because there aren’t sufficiently many different keys to choose from: it only takes six times longer for an attacker to try out every possible key than it would take us to use the secret key we chose in advance.
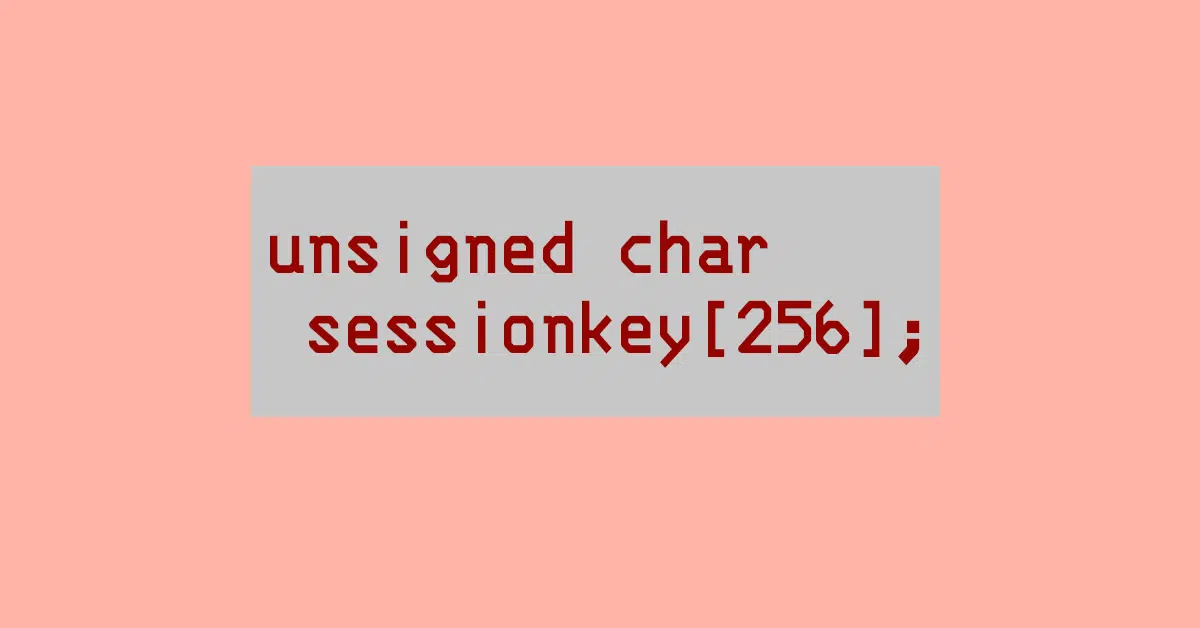
But what if we expand our model, in our imagination at least, to make the number of possible plaintexts and the number of possible keys truly huge, for example by allowing 128 bits of input (16 bytes), and using 128 bits for the key, just like the AES-128 flavor of the Advanced Encryption Standard that we use for encryption today?
If we agree on a secret key in advance, an attacker who intercepts our ciphertext won’t be able to figure out how to decrypt it, because they won’t know which row of the grid we agreed on to do the scrambling and unscrambling.
If the encryption permutations in the grid are truly random (which means the decryption rows are random, too), then there is no algorithmic trickery or predictability that an attacker can exploit to help them crack the code.
Generally speaking, they have to try every possible key, all 2128 of them, a number that’s not only bigger than the number of stars in the Milky Way, but much bigger than the likely number of stars in the entire universe.
(Note that we don’t need to keep the grids themselves secret, only the row number of the encryption and decryption permutations that we used as our secret key.)
Validating the model
Clearly, it’s impossible to build an encryption system this way, because the grids are too large.
If there are 2128 rows in the grid, one for each possible key, each consisting of a list of 2128 columns, one for each possible input, then our grids have 2128 × 2128 = 2256 entries each.
That’s far more than the total number of protons on earth, so we’d have no way to store the grids, even if we had time to generate every column in every row.
Nevertheless, this is, in theory at least, a perfectly sound model of how the real-life encryption system AES-128 works.
Raw AES-128 encrypts in chunks of 16 bytes at a time, using a 16-byte key, so if we had the time and the space, we could indeed pre-calculate complete lookup tables for encryption and decryption.
With these imaginary grids, we could list every possible encryption and every corresponding decryption, of all possible 2128 plaintexts and ciphertexts, for all possible 2128 keys.
Indeed, straight-up AES encryption is known as AES-ECB, short for electronic code book mode, for precisely this reason.
AES-ECB behaves like our theoretical grids with 2256 entries each, but is realized in the practical form of two compact mathematical algorithms (one for encryption and the other for decryption) that can be implemented in a few hundred lines of portable C code.
Let’s accept, therefore, that although our explicitly enumerated encryption-and-decryption grids are impossible in practice, they serve as a valid theoretical mathematical model of a secure encryption system.
Extending the model to non-secret encryption
The question now is whether we can extend this model to avoid the need for a secure channel over which to share a secret key first.
Ellis’s masterful and powerful addition to the model involved two changes: he created separate keys for encryption and decryption, instead of using the same key to lock and unlock; and he involved the recipient in setting up the encryption, instead of having the sender or some central authority specify in advance which key both sides should use.
Here’s how the split-into-two-parts encryption-and-decryption process works.
Instead of creating the decryption grid as a line-by-line inverse of the encryption grid, as we did above, Ellis created a randomly-reordered permutation of the encryption grid instead, so that the encryption and decryption keys didn’t line up directly.
In this example, we’ve constructed the first line of the decryption grid from line 2 of the encryption grid; the second from line 4 of the encryption grid, and so on, randomly mixing up the decryption grid as shown here:
While creating this randomly-reordered grid, we’ve kept a key mapping list L to remember which line of the encryption grid was selected for each of the decryption keys 1, 2, 3, 4, 5 and 6:
No secret key needed in advance
We’ve done it!
We no longer need to agree on a combined encryption-and-decryption key up front.
The recipient decides which decryption key they will use, which we’ll call D, but doesn’t tell the sender what it is.
Instead, they use the randomly-generated key mapping list L to look up which encryption key E goes with D, and then publicly transmit the value of E to the sender.
The sender then encrypts the plaintext P with the publicly-revealed encryption key E to produce a ciphertext message C, which the sender transmits publicly back to the recipient.
The recipient, who chose D to start with but kept it to themselves, can now privately use D to unscramble C, and thereby recover the original message P.
No secure channel is needed.
Remember we are assuming not only that an attacker knows all three tables (the two grids and the key mapping list L are effectively the encryption algorithm, which isn’t secret), but also that they know both the encryption key E and the resulting ciphertext C, because they were transmitted publicly and could therefore have been intercepted.
But this still isn’t enough to reverse the encryption and recover the plaintext P.
That’s because the key mapping list L only works forwards.
It’s easy for the recipient to convert D into E, but an attacker who wants to go backwards from E to D has to search through the entire list for a match.
Likewise, although the attacker knows which line of the encryption grid was used to convert P into its encrypted equivalent C, the encryption grid also only works forwards.
So, an attacker who wants to go backwards from the ciphertext to the plaintext has to search through the entire list for a match.
Cracking this system therefore requires the same brute-force approach as cracking a secret-key system like AES.
You can run through every decryption key in the list L one-by-one until you find the entry that maps onto the encryption key you intercepted, or you can try every possible plaintext in the relevant row in the encryption grid until you find the entry that matches the ciphertext you intercepted.
Ellis suggested having 2100 possible keys, and 2100 different possible messages, handily making the number of iterations in a brute-force attack the same whether you tried searching through all possible decryption keys or through all possible plaintexts.
Brilliantly simple.
Intriguingly, the sender is in a similar position to an attacker after they’ve done the encryption: they don’t know which decryption key matches the encryption key they were sent, so that they can’t decrypt the ciphertext either. This leads to the trick abused to this day by ransomware criminals. They do the encryption on your computer with a key that they can make public, for example by embedding it inside a malware program; then they delete your original files, which means you can’t do the decryption without their help. Even if you or your SOC team extract the encryption key, you no longer have the plaintext of your data, and only the criminals have the decryption key you need to get it back.
Theory versus reality
The problem, as Ellis himself admitted, was that:
“This may seem a specious [encryption system] on the grounds that the effort of making, say, 2100 [brute-force] trials is regarded as prohibitive for the interceptor, while [constructing] a device containing 2200 entries is accepted for the authorised communicator.”
But we already saw that the ‘imagine two impossibly large grids’ approach was a satisfactory way of modelling AES secret-key encryption, for which a practical implementation does exist…
…so it’s perfectly reasonable to accept Ellis’s model of a non-secret encryption process as well, and to agree that the orthodoxy that you always need a secret key and a way to share it in advance is wrong.
We have our existence proof, so we know that the goal of non-secret encryption is worth pursuing, and we can move on to Ellis’s practical follow-up questions:
“Firstly, ‘Would a practical model be similar to the theoretical one?’ and secondly, ‘Can machines having the essential properties of the [random grids and the key mapping list] be devised?'”
Although Ellis didn’t get as far as a practical implementation himself, he did suggest at the end of his report, based on the work he had done already, that “one feels that a solution probably does exist.”
His enthusiasm was well-founded, because algorithms to make his non-secret encryption system possible in real life were invented and documented in 1973 by two of his colleagues, Clifford Cocks and Malcolm Williamson.
Number theory to the rescue
Unlike Ellis, Cocks and Williamson weren’t cryptographers, but were mathematicians who specialized in number theory, which is the study of integers (whole numbers such as 0 and 1, rather than fractions like ½ or irrational numbers such as π) and how they interact.
The pair therefore had handy insights into how to replace Ellis’s unachievably large lookup tables with a compact sequence of mathematical computations that provided equivalent real-life resistance to being cracked.
Both inventors looked for mathematical functions that could generate a matching pair of encryption and decryption keys on demand, but such that knowing the encryption key alone was not enough to work backwards to calculate the decryption key, and knowing the ciphertext alone was not enough to figure out anything about the plaintext from which it was computed.
Cocks decided that very large prime numbers would do the trick, and indeed they did.
It’s easy to generate giant prime numbers P and Q (numbers that can’t be evenly divided by any smaller number), and easy to multiply them together to get N = PQ, even if P and Q are each 1000 digits long.
But it’s as good as impossible, due to the number of trial divisions needed to stumble upon the answer, to split, or factor, N back into P and Q.
If you know either P or Q, you can just calculate Q = N/P or P=N/Q, but if both P and Q are kept secret, you’re sunk.
Combined with a mathematical principle known as Fermat’s Little Theorem, Cocks had the mathematical functions he needed, where the number N was enough on its own to do the encryption calculations, but the corresponding decryption was impossible without knowing P and Q as well.
Williamson figured that a calculation known as modular exponentiation would work, too, and it did.
In modular exponentiation, you calculate a power such as Gr, but you prevent the answer getting bigger and bigger indefinitely by dividing the answer after each step of the calculation by a modulus N, and keeping only the remainder, which can clearly never be larger than N.
(Clock arithmetic, where the time gets to 23:59 and then wraps round back to 00:00, is just modular arithmetic with N = 24, the number of hours in a day.)
It turns out that although working forwards to calculate a modular exponent is easy (multiplications just are repeated additions, and exponents are just repeated multiplications), working backwards from a modular exponent to calculate its inverse, known as the logarithm, is as good as impossible.
The continual ‘wrapping around’ of the exponent every time the calculation gets bigger than the modulus N makes it impossible to estimate what value you are aiming for when you try to work out the logarithm, so there is no way to guide your calculations to home in on it – you have no choice but to find it by brute force.
Solved, but not complete
The story, of course, didn’t finish cleanly in 1973 once the problem was solved.
As you know, we don’t use the term non-secret encryption today, referring instead to public-key cryptography or to asymmetric encryption.
And the best known algorithms for public-key cryptography, generally described in textbooks as ‘the first ones known’, are DHM and RSA, named after the trio of American mathematicians associated with each of them: Whitfield Diffie, Martin Hellman and Ralph Merkle; and Ron Rivest, Adi Shamir and Leonard Adelman.
No one refers to the ECW algorithms, short for Ellis, Cocks and Williamson, even though their work was completed in 1973, while DHM and RSA only came out in 1976 and 1977 respectively.
Cocks came up with his prime number-based algorithm first, which inspired Williamson to follow up shortly after with his modular exponentiation system; amusingly, perhaps, Cocks’s algorithm is essentially the same as RSA, while Williamson’s is identical to DHM, meaning that that the Americans invented their algorithms in the opposite order to the British.
But the British government decided not to adopt non-secret encryption, even though they knew how to make it work, perhaps reasoning that if they revealed that they had it then everyone else would quickly get it too.
Instead, they rather weirdly decided to keep the algorithms and even their interest in researching them secret and classified until December 1997, two decades after both DHM and RSA were announced to the world.
Even when the inventors behind DHM and RSA set about patenting their algorithms, which could have complicated the British government’s ability to use its own inventions in the future, the government decided not to oppose the patent applications.
Apparently, the British view was that patenting software and algorithms probably wasn’t legally possible (how wrong that turned out to be!), so publicly opposing the applications in America would needlessly reveal the British establishment’s cryptographic skills to the world, and perhaps put other countries on their guard.
Ellis, whose identity and achievement become something of an open secret inside the cryptographic community, is wryly supposed to have remarked to Whitfield Diffie when they met informally in 1982:
You did a lot more with it than we did.
Perhaps the full list of reasons why the British insisted on keeping their story secret for so long is best left buried in the mists of time.
James Ellis spent almost three decades as the unacknowledged pioneer of public-key cryptography, but sadly died in November 1997, just three weeks before the British authorities finally lifted the veil of secrecy over his work by declassifying it.
Why not ask how SolCyber can help you do cybersecurity in the most human-friendly way? Don’t get stuck behind an ever-expanding convoy of security tools that leave you at the whim of policies and procedures that are dictated by the tools, even though they don’t suit your IT team, your colleagues, or your customers!
More About Duck
Paul Ducklin is a respected expert with more than 30 years of experience as a programmer, reverser, researcher and educator in the cybersecurity industry. Duck, as he is known, is also a globally respected writer, presenter and podcaster with an unmatched knack for explaining even the most complex technical issues in plain English. Read, learn, enjoy!
Featured image by Nathalia Segato via Unsplash.



 - SolCyber")
 - SolCyber")
 - SolCyber")
 - SolCyber")
 - SolCyber")
 - SolCyber")
 - SolCyber")